
-

Gain 1.5 years of Research Project Experience Certificate
-
100% Job Guaranteed
-
320+ hours Live Interactive Sessions with Eminent Data Scientists
-
Scholarships from day one up to Rs 2 lakhs



-
Become an IBM Certified Data Science Architect Professional
-
Remote or Hybrid International internship opportunities in USA, UK, Europe & APAC for Merit Students with 2 years of Project Experience Certificate
-
Job Guarantee* Program in collaboration with Top PAN India Consulting Firms.
-
Hackathons (Cash rewards upto Rs.1 Lakh will be awarded to top performers)
-
320+ hours Live Interactive Sessions with Eminent Data Scientists
-
Opportunity to conduct research work with GEEKLURN AI Singapore




-
Gain 1.5 years of Research Project Experience Certificate
-
100% Job Guarantee*
-
320+ hours Live Interactive Sessions with Eminent Data Scientists
-
Scholarships from day one up to Rs 2 lakhs

2200+
Alumni Students

Online
Format

24 Months
Program Duration

110+
Hiring Partners

EMI Options
No Cost EMI






-
24-Months Course Duration
- 6 Months of live interactive classes with Principal/Senior industry Data Scientists
- 18 Months of Sponsored Project Work at Authorised Research Centres funded by IISC, ISB, IIM

-
320+ hours Live Interactive Sessions with Eminent Data Scientists.
-
Gain 1.5 years of real-time sponsored Project Expierence Certificate from recognised research centres

-
Start paying your EMI only after placements at the end of the course

-
100% Job Guarantee Program in collaboration with Top HR Consulting Firms across India

-
Scholarships from day ONE up to Rs 2 lakhs based on the type pf Research Projects

-
Get the opportunity to conduct research work with Singapore based GEEKLURN AI
-
50+ Sponsored & Funded Research Projects

-
Get Certified from Top Companies (IBM, Accenture, Microsoft, Oracle...)


Job Guarantee*
Secure exciting Data Science jobs in top companies through our network of over 500 hiring partners and HR companies.

4 million+ Data Jobs
Data Science professionals earn an average salary of ₹16 lakhs, with professionals getting a minimum 30% salary hike compared to the previous jobs.

1-on-1 Career Mentorship
Enhance your resume, prepare for technical interviews, and gain career growth hacks with valuable insights from industry experts and principal data scientists.

Easy Financing Options
GeekLurn offers an easy financing option at 0% interest rate with no hidden costs.

30% Average Salary Hike

16 LPA Average Salary

8000 + Jobs Sourced

500+ Hiring Partners













































































Stage 1
A conducive learning environment with 6 months of live interactive real-time training sessions with 1:1 mentorship offered by top industry experts who are working as Principal & Senior Data Scientists

Stage 2
After hands-on applied training, start working as a Data Science Intern on real-time industry assignments at an authorized GeekLurn incubation zone, which is recognised as a trusted research centre and is funded by IISC, IIM and ISB.

Stage 3
Get an opportunity to work on real- time industry-led projects officially funded by IISC, ISB and IIM. By displaying efficiency, calibre and good performance, you can be eligible for a scholarship of up to Rs. 2 lakh

Stage 4
The successful completion of the project will fetch you an Experience Certificate of 1+years issued by the respective research centre and will to help you add credible projects to your resume, which will prove to be advantageous during placements.

Stage 5
Along with the Experience Certificate, you can fine-tune your resume by getting certified as a Data Science Specialist accredited by top brands in the industry like Microsoft, IBM, HarvardX, DASCA, and SAS.

Stage 6
With 100% Job Guarantee & career support from industry experts in resume building and mock interviews practices, you will be eligible to get hired by more than 110+ Data Science Companies across India and earn up to Rs. 25 lacs/annum

Stage 7
From the 7th months after the completion of the live training session, you can start attending interviews while simultaneously working on research projects.


























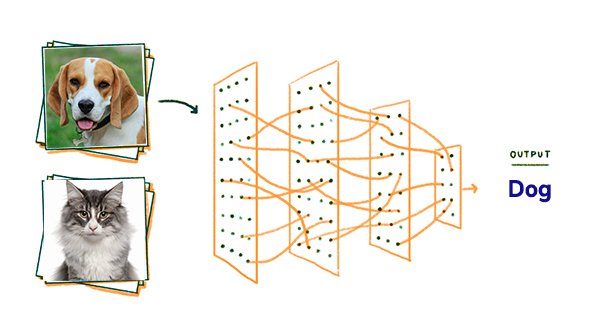
Identifying and classifying images between animals using CNN architecture according to its visual content
The main objective is to classify whether the image is of Dog or a Cat using CNN Architecture.

Developing a Machine Learning based Predictor to predict the different brand Laptop price
The main objective is to predict the price of different brand laptops based on their configurations.

Spam Classifier
The main objective is built an AI-ML model that can classify any SMS/Emails into Spam or Not Spam Message.

A content based movie recommender engine using cosine similarity
The main objective is to build a content based movie recommendation engine using cosine similarity
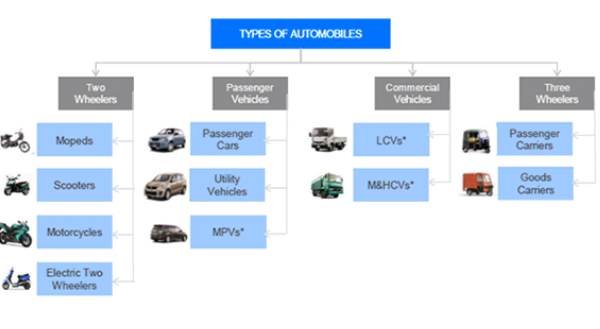
Vehicle Brand Classification using Densenet
The main objective is to identify and classify multiple brand vehicles

A content based anime recommender engine using cosine similarity
The main objective is to build a content based anime recommendation engine using cosine similarity

Deep Learning Facial Recognition Multi Task Cascade project using CNN archtiecture
The main objective is identifying similar faces and check various aspects in pictures which includes: facial shape, its skin tonality and positions and other aspects of facial parts

Analyzing behavioral pattern using Whatsapp Chat Data
The main objective is to analyze the behavioural pattern of individuals and understand how the behavioural pattern changes when they are conversing alone and when they are in social circle

Toxicity classification with Natural Langauage Processing using BERT Transformers
The main objective is to build a multi-headed model that's capable of detecting different types of toxicity like threats,obscenity, insults, and identity-based hate. The dataset is of comments from Wikipedia's talk page edits




Guidance from Corporate Specialists
Resolve all theory and project related queries from our with our mentors, who are eminent industry experts.
Corporate Boost Camps
Participate in workshops and live webinars to understand technical terms and trends and make your learning reasonable.
Peer Networking
Build a cohesive learning network with workmates, mentors, and experts to share ideas, address intra-queries, and resolve projects, and practical learning ambiguities.

Placement Guarantee
Our one-of-a-kind learning program promises 100% Job Guarantee and prepares you to be industry ready and equipped with all the requisites for a successful career in Data Science Industry.






